AI-MX Memory bandwidth acceleration
AI inference performance is increasingly constrained by memory bandwidth and capacity - not compute. Especially in large language models (LLMs), where the Prefill stage is compute-bound, but the Decode stage - critical for low-latency, real-time applications - is memory-bound. Traditional approaches like quantization, pruning and distillation reduce memory usage but compromise accuracy.
ZeroPoint’s AI-MX offers a complementary solution: lossless, nanosecond-latency memory compression, enabling up to 1.5x more effective HBM or LPDDR capacity and bandwidth. AI-MX enhances AI accelerators by transparently compressing memory traffic - without changes to DMA logic or SoC architecture.
Overview
AI inference performance is increasingly constrained by memory bandwidth and capacity - not compute. Especially in large language models (LLMs), where the Prefill stage is compute-bound, but the Decode stage - critical for low-latency, real-time applications - is memory-bound. Traditional approaches like quantization, pruning and distillation reduce memory usage but compromise accuracy.
ZeroPoint’s AI-MX offers a complementary solution: lossless, nanosecond-latency memory compression, enabling up to 1.5x more effective HBM or LPDDR capacity and bandwidth. AI-MX enhances AI accelerators by transparently compressing memory traffic - without changes to DMA logic or SoC architecture.
Standards
Compression: XZI (proprietary)
Interface: AXI4, CHI
Plug in compatible with industry standard memory controllers
Architecture
Modular architecture, enables seamless scalability
Architectural configuration parameters accessible to fine tune performance
HDL Source Licenses
Synthesizable System Verilog RTL (encrypted)
Implementation constraints
UVM testbench (self-checking)
Vectors for testbench and expected results
User Documentation
Features
SW model compression and in-line hardware accelerated decompression (Gen 1)
Hardware accelerated in-line compression and decompression (Gen 2)
On-the-fly Multi-algorithm switching capability without recompression
Cache line granularity to enable high throughput and low latency
Deliverables
Performance evaluation license C++ compression model for integration in customer performance simulation model
FPGA evaluation license
Encrypted IP delivery (Xilinx)
Applications
AI Inference Accelerators (Datacenter, Edge)
Generative AI (LLMs like LLaMA3, GPT, Claude)
Smart devices with LPDDR bottlenecks
Automotive & Embedded AI Systems
Any SoC using HBM, LPDDR, GDDR or DDR
AI-MX unlocks new levels of AI performance and efficiency, enabling accelerators to do more with less while keeping latency to a minimum.
Integration
AI-MX is available in two versions:
AI-MX G1 - Asymmetrical Architecture
Models are compressed in software before deployment
Hardware performs in-line decompression at runtime
Suitable for static model data
Up to 1.5x expansion
AI-MX G2 - Symmetrical Architecture
Full in-line hardware compression + decompression
Accelerates not just the model, but also KV-cache, activations, and runtime data
Up to 2x expansion on unstructured data
Ideal for dynamic, memory-bound workloads
Key Benefits
+50% Effective HBM Capacity - Compress model and runtime data to fit 150 GB of workload into 100 GB of physical memory.
+50% Bandwidth Efficiency - Transfer more data per memory transaction, accelerating model throughput - tokens per second - without increasing power.
+50% More Throughput from the Same Silicon - An AI accelerator with 4 HBM stacks behaves like it has 6 - without changing the memory controller.
Transparent System Integration - Includes a patented, real-time Address Translation Unit for seamless compressed memory access.
Performance / KPI
| Feature | Performance |
| Compression ratio: | 1.5x for LLM model data at BF16
1,35x - 2.0x for dynamic data i.e. KV cache and activiations |
| Throughput: | Matches the throughput of the HBM and LPDDR memory channel |
| Frequency: | Up to 1.75 GHz (@5nm TSMC) |
| IP area: | (Throughput dependant - contact for information) |
| Memory technologies supported: | HBM, GDDR, LPDDR, DDR, SRAM |
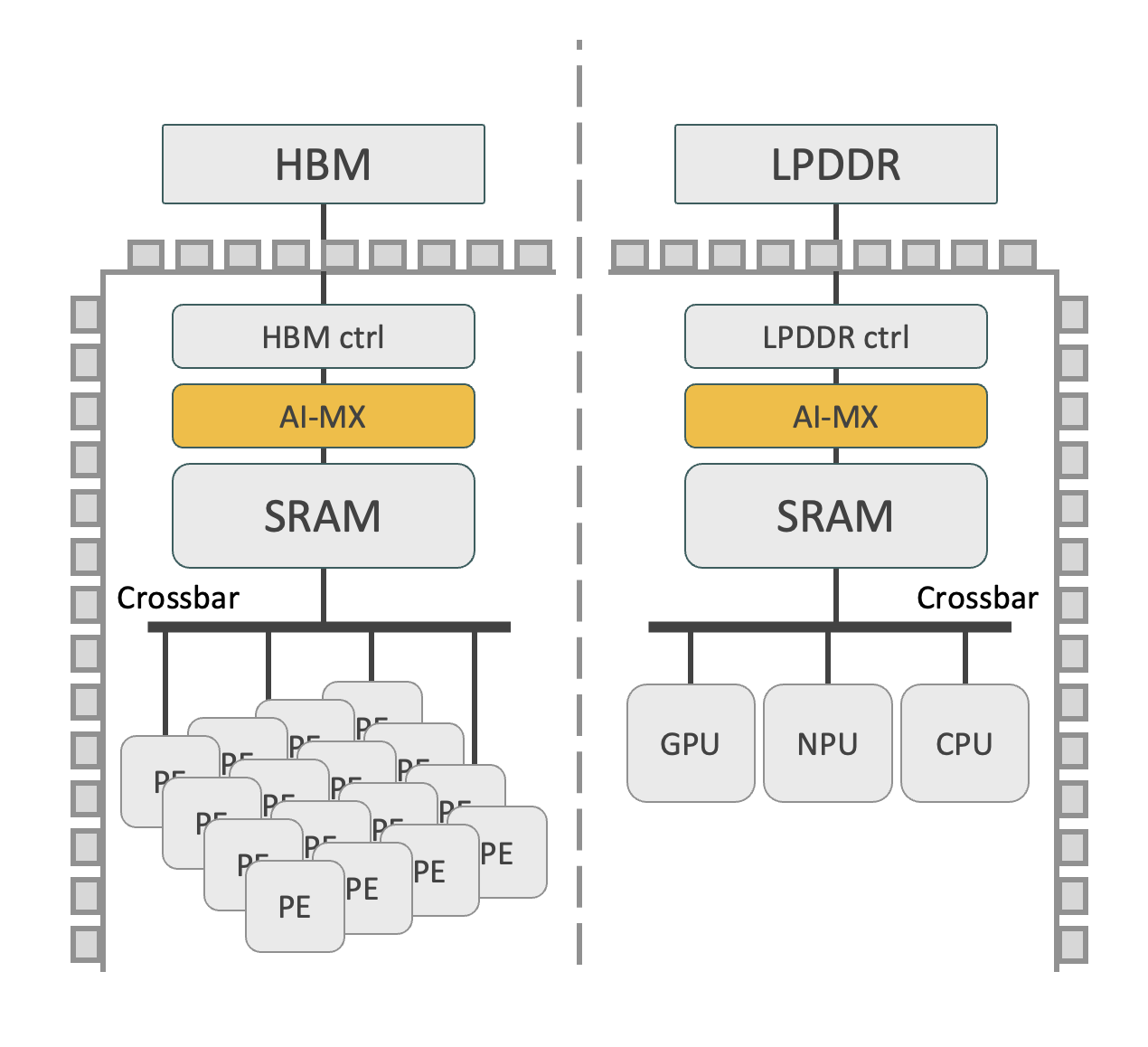
System integration with AI-MX
AI.-MX is integrated on the memory access path, intercepting the data sent to and from memory. Depending on the application (Server CPU, GPU, xPU, or Smart devices) the preferred interfaces are AXI4 and CHI.